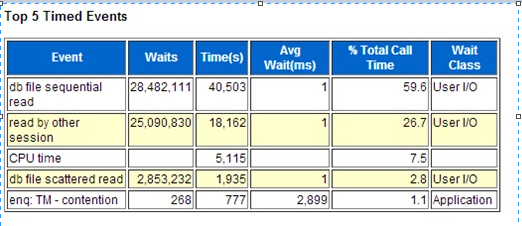
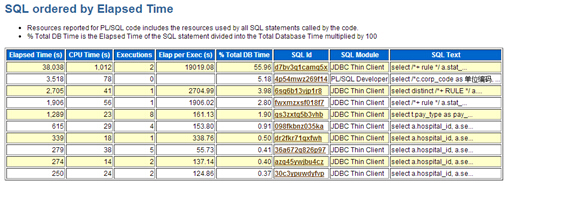
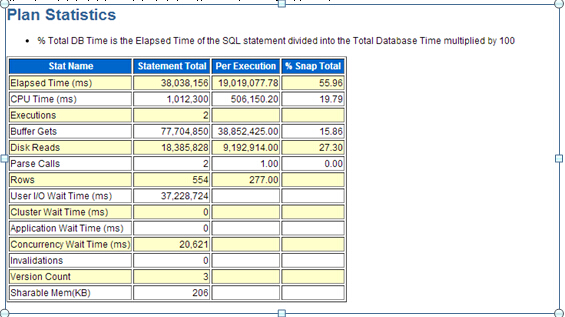
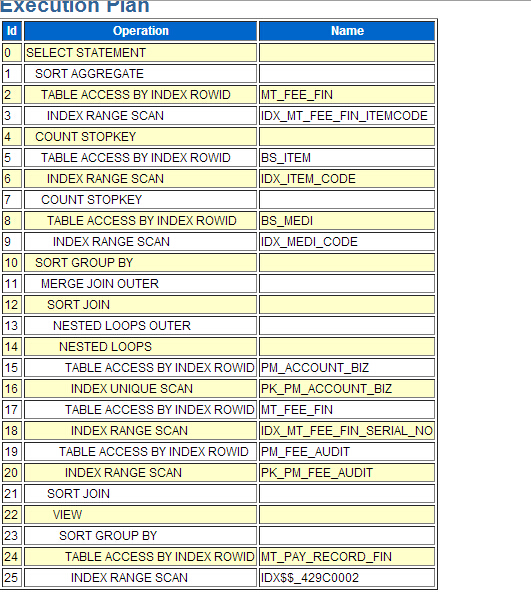
设置闪回区的情况下还原控制文件所使用的命令是相同的。然而如果当前数据库正在使用闪回区,RMAN通过对所有基于控制文件中的基于磁盘的备份和镜像副本和任何在闪回区中而不在还原的控制文件中的备份执行隐式的crosscheck来更新从备份中还原的控制文件。因此还原后的控制文件会完整的和精确的记录在闪回区中的所有备份和其它任何在备份该控制文件时所知道的备份。这提高了在数据库还原操作中的可用性。
下面来看一个使用闪回区还原控制文件的实例:
1.环境检查,看是否已经启用闪回区与设置控制文件自动备份
SQL> show parameter db_recover NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_recovery_file_dest string /u01/app/oracle/flash_recovery_area db_recovery_file_dest_size big integer 2G SQL> select flashback_on from v$database; FLASHBACK_ON ------------------ YES RMAN> show controlfile autobackup; RMAN configuration parameters are: CONFIGURE CONTROLFILE AUTOBACKUP ON;
从上面信息可知已经启用了闪回区并设置了控制文件自动备份
2.创建一个表空间,在数据库结构发生变化时,就会自动备份控制文件
SQL> create tablespace testbak datafile '/u01/app/oracle/oradata/test/testbak.dbf' size 10M extent management local segment space management auto; Tablespace created.
从alert日志中可以看到产生的控制文件自动备份的文件信息
create tablespace testbak datafile '/u01/app/oracle/oradata/test/testbak.dbf' size 10M extent management local segment space management auto
Mon Feb 02 00:17:28 CST 2015
Starting control autobackup
Control autobackup written to DISK device
handle '/u01/app/oracle/flash_recovery_area/TEST/autobackup/2015_02_02/o1_mf_s_870567448_bdwndtqk_.bkp'
Completed: create tablespace testbak datafile '/u01/app/oracle/oradata/test/testbak.dbf' size 10M extent management local segment space management auto
其实控制文件和spfile同时被自动备份了
查看闪回区是否存在自动备份文件
[root@oracle11g 2015_02_02]# ls -lrt total 19360 -rw-r----- 1 oracle oinstall 9895936 Feb 2 00:17 o1_mf_s_870567448_bdwndtqk_.bkp
3.人为删除所有控制文件
[root@oracle11g test]# ls -lrt total 2213868 -rw-r----- 1 oracle oinstall 20979712 Feb 1 11:37 temp01.dbf -rw-r----- 1 oracle oinstall 11804672 Feb 1 22:31 users01.dbf -rw-r----- 1 oracle oinstall 52436992 Feb 1 22:31 test01.dbf -rw-r----- 1 oracle oinstall 52429312 Feb 1 22:31 redo03.log -rw-r----- 1 oracle oinstall 52429312 Feb 1 22:31 redo02.log -rw-r----- 1 oracle oinstall 104865792 Feb 1 22:31 example01.dbf -rw-r----- 1 oracle oinstall 576724992 Feb 1 22:37 sysaux01.dbf -rw-r----- 1 oracle oinstall 492838912 Feb 1 22:42 undotbs01.dbf -rw-r----- 1 oracle oinstall 838868992 Feb 1 22:42 system01.dbf -rw-r----- 1 oracle oinstall 52429312 Feb 1 22:42 redo01.log -rw-r----- 1 oracle oinstall 9814016 Feb 1 22:42 control03.ctl -rw-r----- 1 oracle oinstall 9814016 Feb 1 22:42 control02.ctl -rw-r----- 1 oracle oinstall 9814016 Feb 1 22:42 control01.ctl [root@oracle11g test]# rm -rf control*.ctl [root@oracle11g test]# ls -lrt total 2185068 -rw-r----- 1 oracle oinstall 20979712 Feb 1 11:37 temp01.dbf -rw-r----- 1 oracle oinstall 11804672 Feb 1 22:31 users01.dbf -rw-r----- 1 oracle oinstall 52436992 Feb 1 22:31 test01.dbf -rw-r----- 1 oracle oinstall 52429312 Feb 1 22:31 redo03.log -rw-r----- 1 oracle oinstall 52429312 Feb 1 22:31 redo02.log -rw-r----- 1 oracle oinstall 104865792 Feb 1 22:31 example01.dbf -rw-r----- 1 oracle oinstall 576724992 Feb 1 22:37 sysaux01.dbf -rw-r----- 1 oracle oinstall 492838912 Feb 1 22:42 undotbs01.dbf -rw-r----- 1 oracle oinstall 838868992 Feb 1 22:42 system01.dbf -rw-r----- 1 oracle oinstall 52429312 Feb 1 22:42 redo01.log
4.人为将数据库异常终止
[root@oracle11g test]# ps -ef | grep smon oracle 3068 1 0 22:30 ? 00:00:00 ora_smon_test root 3179 3123 0 22:45 pts/3 00:00:00 grep smon [root@oracle11g test]# kill -9 3068
5.将数据库启动到nomount状态
SQL> startup nomount ORACLE instance started. Total System Global Area 327155712 bytes Fixed Size 1273516 bytes Variable Size 138412372 bytes Database Buffers 184549376 bytes Redo Buffers 2920448 bytes
6.恢复控制文件
RMAN> restore controlfile from autobackup; Starting restore at 02-FEB-15 allocated channel: ORA_DISK_1 channel ORA_DISK_1: sid=148 devtype=DISK recovery area destination: /u01/app/oracle/flash_recovery_area database name (or database unique name) used for search: TEST channel ORA_DISK_1: autobackup found in the recovery area channel ORA_DISK_1: autobackup found: /u01/app/oracle/flash_recovery_area/TEST/autobackup/2015_02_02/o1_mf_s_870567448_bdwndtqk_.bkp channel ORA_DISK_1: control file restore from autobackup complete Finished restore at 02-FEB-15
在上面的还原控制文件的过程可以看到如下内容说明是使用存储在闪回区中的控制文件自动备份来还原控制文件
channel ORA_DISK_1: autobackup found in the recovery area channel ORA_DISK_1: autobackup found: /u01/app/oracle/flash_recovery_area/TEST/autobackup/2015_02_02/o1_mf_s_870567448_bdwndtqk_.bkp
磁带备份在还原控制文件后不会自动执行crosscheck。如果正使用磁带备份,那么在还原控制文件并将数据库置于mount状态后,必须手工执行crosscheck.
RMAN> CROSSCHECK BACKUP DEVICE TYPE SBT;
7.执行完全恢复
RMAN> sql 'alter database mount'; sql statement: alter database mount released channel: ORA_DISK_1 RMAN> recover database; Starting recover at 01-FEB-15 Starting implicit crosscheck backup at 01-FEB-15 allocated channel: ORA_DISK_1 channel ORA_DISK_1: sid=155 devtype=DISK Crosschecked 8 objects Finished implicit crosscheck backup at 01-FEB-15 Starting implicit crosscheck copy at 01-FEB-15 using channel ORA_DISK_1 Crosschecked 6 objects Finished implicit crosscheck copy at 01-FEB-15 searching for all files in the recovery area cataloging files... no files cataloged using channel ORA_DISK_1 starting media recovery archive log thread 1 sequence 3 is already on disk as file /u01/app/oracle/oradata/test/redo03.log archive log thread 1 sequence 4 is already on disk as file /u01/app/oracle/oradata/test/redo01.log archive log filename=/u01/app/oracle/oradata/test/redo03.log thread=1 sequence=3 archive log filename=/u01/app/oracle/oradata/test/redo01.log thread=1 sequence=4 media recovery complete, elapsed time: 00:00:01 Finished recover at 01-FEB-15 RMAN> sql 'alter database open resetlogs'; sql statement: alter database open resetlogs new incarnation of database registered in recovery catalog starting full resync of recovery catalog full resync complete