Library cache
在提出好的库缓存性能解决方案之前,您需要对库缓存的体系结构有一个充分的了解。有了这些知识,以及前几章介绍的背景知识,您就能够理解为什么一个解决方案是有意义的,以及它可能产生的影响。
Library Cache架构
library cache架构是非常复杂的。并发性、对象之间的关系和快速搜索的组合需求确实会对体系结构造成压力。我将从这个体系结构的一个非常概念性的层次开始,然后有条不紊地深入到越来越多的细节。当细节对性能救火没有特别帮助时,我将停止。
一个很好的library cache模型是传统library。假设你想找雷·布拉德伯里的书《蒲公英酒》。因为图书馆是一个巨大的图书仓库(想想所有的缓存对象),顺序或随机搜索都是徒劳的。因此,您进入卡片目录区域(哈希结构),并直接访问包含以字母A到D开头的作者的书籍的卡片目录(考虑哈希到一个特定的桶)。在你前面有人排队,因此你必须等待(这就好比获取相关哈希桶的latch一样)。最后你站在了适当的卡片目录前面(就好像你获得了latch)并开始序列化搜索图书(就好像序列化搜索一个哈希chain)。最终你找到了卡片并看到了图书的地址为813.54(就好像library cache handle)。你走到图书应该存放的位置,找到它并开始阅读(就好像访问游标一样)。如果您能够在脑海中描绘这个故事,那么您就已经很好地理解了Oracle的库缓存。
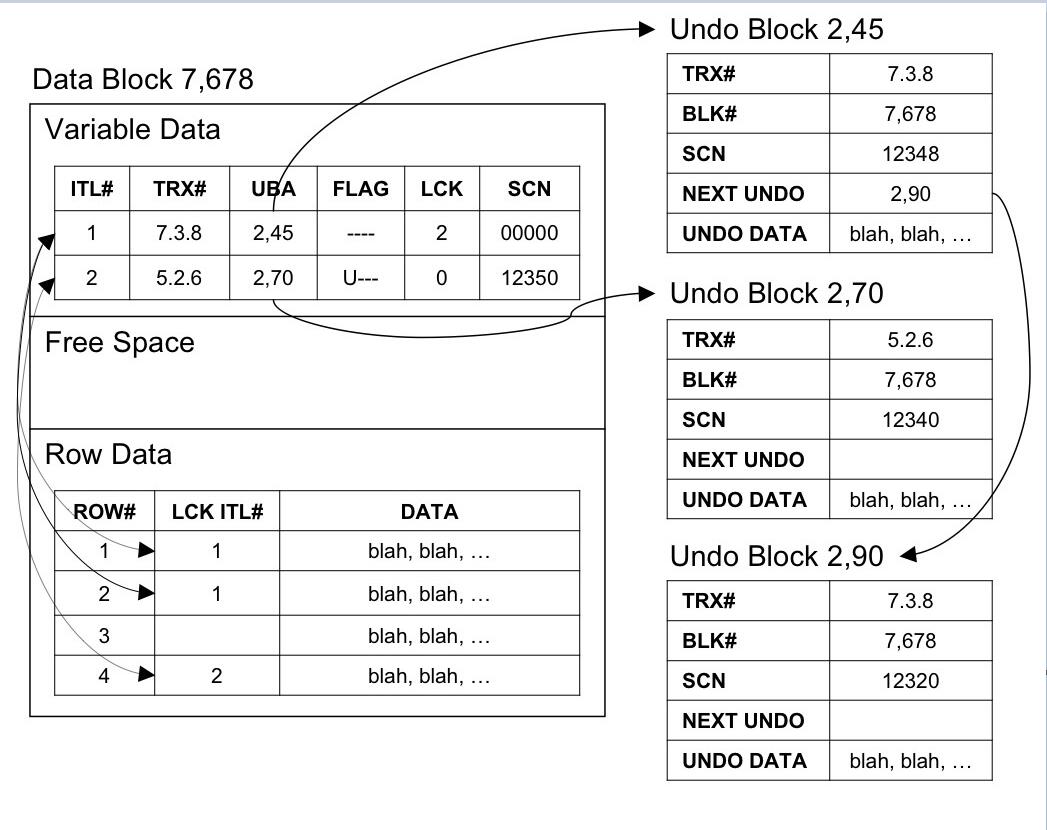
Library Cache Conceptual Model
与buffer cache一样,library cache对象使用一种哈希结构来进行定位。这将调用哈希函数,桶,链表与latches或mutexes。一个关键的不同点是哈希链节点不是由buffer headers组成的,而是称为句柄(handles)的简单指针节点。
句柄是内存地址指针的常用术语,这就是library cache的情况。在一个handle与一个library cache内存对象之间是一对一的关系。所以引用句柄与引用它的关联对象是同义词操作。当mutexes被用来替代library cache latches时,每个单独的handle都有一个相关的mutex。每个library cache对象引用一个特定类型的对象,有时叫命名空间,比如一个游标,一个子游标,一个表或一个程序结构。
下图抽象了library cache对mutexes的实现以及突显了各种架构组件但没有指定对象名称。Library cache对象使用一种哈希结构来进行搜索,因此可以看到桶,比如bucket BKT200。当实同mutexes时,对于每个handle都有一个相关的mutex,因此每个内存chunk有一个相关的mutex。每个哈希链可能包含零个或多个handles,它与零个或多个library cache对象相关,比如游标 CSR500与表TBL 400。每个父游标将至少有一个子游标。一个父游标比如CSR 500可以与多个子游标,比如CCSR 600和CCSR 610相关联。
一种关键的library cache特点就是对象关系。在上图中,注意表TBL 400与三个子游标CCSR 600,CCSR 610和CCSR 620相关联,如果表TBL 400被修改,Oracle知道那些library cache对象将会失效。例如,如果表TBL 400被修改了并且Oracle认为这种修改非常严重足以使用library cache条目失效,然后所有相关的library cache对象也将失效。当然,必须维护序列化,这样您就可以看到,即使是相对较小的库缓存也会变得非常紧张。
使用mutexes代替latches的影响。因此一个mutex与每个library cache对象相关联,因此不会使整个哈希链不可用,从而显著减少了错误争用和获取CPU消耗,从而提高了响应时间。
Library Cache Object References
现在,让我们将概念模型提升到更实际的层次,以阐明库缓存对象关系。
SQL> oradebug setmypid Statement processed. SQL> alter session set MAX_DUMP_FILE_SIZE=unlimited; Session altered. SQL> create table findme as select * from dual; Table created. SQL> alter session set optimizer_mode = all_rows; Session altered. SQL> select * from findme; D - X SQL> alter session set optimizer_mode = first_rows; Session altered. SQL> select * from findme; D - X SQL> select dummy from findme; D - X SQL> alter session set events 'immediate trace name library_cache level 10'; Session altered. SQL> oradebug tracefile_name /u01/app/oracle/diag/rdbms/jy/jy1/trace/jy1_ora_13777.trc
从跟踪文件中可以看到Bucket 12771与一个对象相关联,表findme的handle为0x8501f820,Bucket 14778相关的handle,mutex,名称和两个子游标。
Bucket: #=12771 Mutex=0xc5b46150(3298534883328, 31, 0, 6)
LibraryHandle: Address=0x8501f820 Hash=7c1631e3 LockMode=0 PinMode=0 LoadLockMode=0 Status=VALD
ObjectName: Name=CDB$ROOT.SYS.FINDME
FullHashValue=29918f78d6b184afaf81fd2b7c1631e3 Namespace=TABLE/PROCEDURE(01) Type=TABLE(02) ContainerId=1 ContainerUid=1 Identifier=246951 OwnerIdn=0
Statistics: InvalidationCount=0 ExecutionCount=0 LoadCount=1 ActiveLocks=0 TotalLockCount=9 TotalPinCount=9
Counters: BrokenCount=2 RevocablePointer=2 KeepDependency=0 Version=0 BucketInUse=6 HandleInUse=6 HandleReferenceCount=0
Concurrency: DependencyMutex=0x8501f8d0(0, 4, 0, 0) Mutex=0x8501f970(768, 96, 0, 6)
Flags=PIN/TIM/[00002801] Flags2=[0000]
WaitersLists:
Lock=0x8501f8b0[0x8501f8b0,0x8501f8b0]
Pin=0x8501f890[0x8501f890,0x8501f890]
LoadLock=0x8501f908[0x8501f908,0x8501f908]
Timestamp: Current=04-23-2019 09:19:22
HandleReference: Address=0x8501fa18 Handle=0xcff01220 Flags=OWN[200]
LockInstance: id='LB29918f78d6b184af' GlobalEnqueue=(nil) ReleaseCount=0
PinInstance: id='NB29918f78d6b184af' GlobalEnqueue=(nil)
ReferenceList:
Reference: Address=0x7f4fa5f0 Handle=0x7f72fd58 Flags=DEP[01]
Timestamp=04-23-2019 09:19:22 InvalidatedFrom=0
Reference: Address=0xbcc24930 Handle=0xd6d3f620 Flags=DEP[01]
Timestamp=04-23-2019 09:19:22 InvalidatedFrom=0
Reference: Address=0xddfa2a28 Handle=0x7fb24eb8 Flags=DEP[01]
Timestamp=04-23-2019 09:19:22 InvalidatedFrom=0
Reference: Address=0x800e41e8 Handle=0x83a9c4e8 Flags=DEP[01]
Timestamp=04-23-2019 09:19:22 InvalidatedFrom=0
LibraryObject: Address=0xdf389690 HeapMask=0000-0701-0001-0000 Flags=EXS/LOC[0004] Flags2=[8000000] PublicFlags=[0000]
DataBlocks:
Block: #='0' name=KGLH0^7c1631e3 pins=0 Change=NONE
Heap=0xb387c0e8 Pointer=0xdf389760 Extent=0xdf3895e8 Flags=I/-/-/A/-/-/-
FreedLocation=0 Alloc=1.304688 Size=3.976562 LoadTime=4629524905
Block: #='8' name=KGLS^7c1631e3 pins=0 Change=NONE
Heap=0xdf389b18 Pointer=0xdb10a550 Extent=0xdb109870 Flags=I/-/-/A/-/-/-
FreedLocation=0 Alloc=1.125000 Size=3.976562 LoadTime=0
Bucket: #=14778 Mutex=0xc5b59ae8(3298534883328, 43, 0, 6)
LibraryHandle: Address=0x818b62f8 Hash=ebf439ba LockMode=0 PinMode=0 LoadLockMode=0 Status=VALD
ObjectName: Name=select * from findme
FullHashValue=57c14570e98dc8b98fe8a5a2ebf439ba Namespace=SQL AREA(00) Type=CURSOR(00) ContainerId=1 ContainerUid=1 Identifier=3958651322 OwnerIdn=0
Statistics: InvalidationCount=0 ExecutionCount=2 LoadCount=3 ActiveLocks=0 TotalLockCount=2 TotalPinCount=1
Counters: BrokenCount=1 RevocablePointer=1 KeepDependency=2 Version=0 BucketInUse=1 HandleInUse=1 HandleReferenceCount=0
Concurrency: DependencyMutex=0x818b63a8(0, 2, 0, 0) Mutex=0x818b6448(768, 37, 0, 6)
Flags=RON/PIN/TIM/PN0/DBN/[10012841] Flags2=[0000]
WaitersLists:
Lock=0x818b6388[0x818b6388,0x818b6388]
Pin=0x818b6368[0x818b6368,0x818b6368]
LoadLock=0x818b63e0[0x818b63e0,0x818b63e0]
Timestamp: Current=04-23-2019 09:19:37
HandleReference: Address=0x818b64d0 Handle=(nil) Flags=[00]
ReferenceList:
Reference: Address=0x8031bbf0 Handle=0x8054ae68 Flags=ROD[21]
Reference: Address=0x80f11e30 Handle=0xdd9f6df8 Flags=ROD[21]
LibraryObject: Address=0x84edddb0 HeapMask=0000-0001-0001-0000 Flags=EXS[0000] Flags2=[0000] PublicFlags=[0000]
DataBlocks:
Block: #='0' name=KGLH0^ebf439ba pins=0 Change=NONE
Heap=0xd2f65218 Pointer=0x84edde80 Extent=0x84eddd08 Flags=I/-/P/A/-/-/-
FreedLocation=0 Alloc=3.390625 Size=3.976562 LoadTime=4629539589
ChildTable: size='16'
Child: id='0' Table=0x84edec30 Reference=0x84ede700 Handle=0x83a9c4e8
Child: id='1' Table=0x84edec30 Reference=0x84edea50 Handle=0xd6d3f620
NamespaceDump:
Parent Cursor: sql_id=8zu55nbpz8fdu parent=0x84edde80 maxchild=2 plk=n ppn=n prsfcnt=0 obscnt=0
CursorDiagnosticsNodes:
ChildNode: ChildNumber=0 ID=3 reason=Optimizer mismatch(10) size=3x4 optimizer_mode_hinted_cursor=0 optimizer_mode_cursor=1 optimizer_mode_current=2
Bucket: #=67700 Mutex=0xc5d5e7f8(3298534883328, 125, 0, 6)
LibraryHandle: Address=0xbd8f26d0 Hash=93850874 LockMode=0 PinMode=0 LoadLockMode=0 Status=VALD
ObjectName: Name=select dummy from findme
FullHashValue=70b1c44268eb8c9d2860b06f93850874 Namespace=SQL AREA(00) Type=CURSOR(00) ContainerId=1 ContainerUid=1 Identifier=2474969204 OwnerIdn=0
Statistics: InvalidationCount=0 ExecutionCount=1 LoadCount=2 ActiveLocks=0 TotalLockCount=1 TotalPinCount=1
Counters: BrokenCount=1 RevocablePointer=1 KeepDependency=1 Version=0 BucketInUse=0 HandleInUse=0 HandleReferenceCount=0
Concurrency: DependencyMutex=0xbd8f2780(0, 1, 0, 0) Mutex=0xbd8f2820(768, 23, 0, 6)
Flags=RON/PIN/TIM/PN0/DBN/[10012841] Flags2=[0000]
WaitersLists:
Lock=0xbd8f2760[0xbd8f2760,0xbd8f2760]
Pin=0xbd8f2740[0xbd8f2740,0xbd8f2740]
LoadLock=0xbd8f27b8[0xbd8f27b8,0xbd8f27b8]
Timestamp: Current=04-23-2019 09:20:01
HandleReference: Address=0xbd8f28b0 Handle=(nil) Flags=[00]
ReferenceList:
Reference: Address=0x8574abf8 Handle=0x7f4cc5c0 Flags=ROD[21]
LibraryObject: Address=0x86991c70 HeapMask=0000-0001-0001-0000 Flags=EXS[0000] Flags2=[0000] PublicFlags=[0000]
DataBlocks:
Block: #='0' name=KGLH0^93850874 pins=0 Change=NONE
Heap=0xbc1721d8 Pointer=0x86991d40 Extent=0x86991bc8 Flags=I/-/P/A/-/-/-
FreedLocation=0 Alloc=2.546875 Size=3.976562 LoadTime=4629563404
ChildTable: size='16'
Child: id='0' Table=0x86992af0 Reference=0x869925c0 Handle=0x7f72fd58
NamespaceDump:
Parent Cursor: sql_id=2hs5hdy9sa23n parent=0x86991d40 maxchild=1 plk=n ppn=n prsfcnt=0 obscnt=0
从下面的内容可以看出子游标之间的关系。
Bucket: #=103006 Mutex=0xc5eb7488(3298534883328, 304, 0, 6)
LibraryHandle: Address=0xdd9f6df8 Hash=2ab9925e LockMode=0 PinMode=0 LoadLockMode=0 Status=VALD
ObjectName: Name=CDB$ROOT.57c14570e98dc8b98fe8a5a2ebf439ba Child:0
FullHashValue=2ccbd3fc5f92a1798e3cc3a22ab9925e Namespace=SQL AREA STATS(75) Type=CURSOR STATS(102) ContainerId=1 ContainerUid=1 Identifier=716804702 OwnerIdn=0
Statistics: InvalidationCount=0 ExecutionCount=0 LoadCount=1 ActiveLocks=0 TotalLockCount=1 TotalPinCount=1
Counters: BrokenCount=1 RevocablePointer=1 KeepDependency=1 Version=0 BucketInUse=0 HandleInUse=0 HandleReferenceCount=0
Concurrency: DependencyMutex=0xdd9f6ea8(0, 1, 0, 0) Mutex=0xdd9f6f48(768, 9, 0, 6)
Flags=RON/PIN/TIM/KEP/KPR/[00012805] Flags2=[0000]
WaitersLists:
Lock=0xdd9f6e88[0xdd9f6e88,0xdd9f6e88]
Pin=0xdd9f6e68[0xdd9f6e68,0xdd9f6e68]
LoadLock=0xdd9f6ee0[0xdd9f6ee0,0xdd9f6ee0]
Timestamp: Current=04-23-2019 09:19:37
ReferenceList:
Reference: Address=0x800e40e0 Handle=0x83a9c4e8 Flags=ROD/KPP[61]
LibraryObject: Address=0x80f119f0 HeapMask=0001-0001-0001-0000 Flags=EXS[0000] Flags2=[0000] PublicFlags=[0000]
ReadOnlyDependencies: count='1' size='16'
ReadDependency: num='0' Table=0x80f12898 Reference=0x80f11e30 Handle=0x818b62f8 HandleFlag=0x10012841 RefFlags=DEP/ROD[21]
DataBlocks:
Block: #='0' name=KGLH0^2ab9925e pins=0 Change=NONE
Heap=0xd2468460 Pointer=0x80f11ac0 Extent=0x80f11948 Flags=I/-/P/A/-/-/-
FreedLocation=0 Alloc=1.265625 Size=3.976562 LoadTime=4629539590
NamespaceDump:
STATS: phd=0x818b62f8 chd=0x83a9c4e8 planhsh=5111da46 flg=1 Parse Count=1 Disk Reads=2 Disk Writes (Direct)=0 Disk Reads (Direct)=0 Physical read requests=2 Physical read bytes=16384 Physical write requests=0 Physical write bytes=0 IO Interconnect bytes=16384 Buffer Gets=27 Rows Processed=1 Serializable Aborts=0 Fetches=2 Execution count=1 PX Server Execution Count=0 Full Execution Count=1 CPU time=15000 Elapsed time=433961 Avg Hard Parse Time=420034 Application time=0 Concurrency time=985 Cluster/RAC time=496 User I/O time=407471 Plsql Interpretor time=0 JVM time=0 Sorts=0
Bucket: #=128596 Mutex=0xc5fb12f8(3298534883328, 137, 0, 6)
LibraryHandle: Address=0x8054ae68 Hash=efe9f654 LockMode=0 PinMode=0 LoadLockMode=0 Status=VALD
ObjectName: Name=CDB$ROOT.57c14570e98dc8b98fe8a5a2ebf439ba Child:1
FullHashValue=35e6477c4d445fa62356ff83efe9f654 Namespace=SQL AREA STATS(75) Type=CURSOR STATS(102) ContainerId=1 ContainerUid=1 Identifier=4025087572 OwnerIdn=0
Statistics: InvalidationCount=0 ExecutionCount=0 LoadCount=1 ActiveLocks=0 TotalLockCount=1 TotalPinCount=1
Counters: BrokenCount=1 RevocablePointer=1 KeepDependency=1 Version=0 BucketInUse=0 HandleInUse=0 HandleReferenceCount=0
Concurrency: DependencyMutex=0x8054af18(0, 1, 0, 0) Mutex=0x8054afb8(768, 9, 0, 6)
Flags=RON/PIN/TIM/KEP/KPR/[00012805] Flags2=[0000]
WaitersLists:
Lock=0x8054aef8[0x8054aef8,0x8054aef8]
Pin=0x8054aed8[0x8054aed8,0x8054aed8]
LoadLock=0x8054af50[0x8054af50,0x8054af50]
Timestamp: Current=04-23-2019 09:19:53
ReferenceList:
Reference: Address=0xbcc24828 Handle=0xd6d3f620 Flags=ROD/KPP[61]
LibraryObject: Address=0x8031b7b0 HeapMask=0001-0001-0001-0000 Flags=EXS[0000] Flags2=[0000] PublicFlags=[0000]
ReadOnlyDependencies: count='1' size='16'
ReadDependency: num='0' Table=0x8031c658 Reference=0x8031bbf0 Handle=0x818b62f8 HandleFlag=0x10012841 RefFlags=DEP/ROD[21]
DataBlocks:
Block: #='0' name=KGLH0^efe9f654 pins=0 Change=NONE
Heap=0xd26770b8 Pointer=0x8031b880 Extent=0x8031b708 Flags=I/-/P/A/-/-/-
FreedLocation=0 Alloc=1.265625 Size=3.976562 LoadTime=4629556046
NamespaceDump:
STATS: phd=0x818b62f8 chd=0xd6d3f620 planhsh=5111da46 flg=1 Parse Count=1 Disk Reads=0 Disk Writes (Direct)=0 Disk Reads (Direct)=0 Physical read requests=0 Physical read bytes=0 Physical write requests=0 Physical write bytes=0 IO Interconnect bytes=0 Buffer Gets=22 Rows Processed=1 Serializable Aborts=0 Fetches=2 Execution count=1 PX Server Execution Count=0 Full Execution Count=1 CPU time=7000 Elapsed time=6158 Avg Hard Parse Time=5220 Application time=0 Concurrency time=0 Cluster/RAC time=0 User I/O time=0 Plsql Interpretor time=0 JVM time=0 Sorts=0
Keeping Cursor in the Cache
构建一个游标是相对昂贵的操作。CPU消耗和将对象放入库缓存的IO可能会显著降低性能。这通常表现为解析CPU消耗的增加,特别是库缓存latch或互斥锁成为最主要的等待事件。因此,一个明显的目标是将游标保存在库缓存中。但是,必须保持平衡,否则会出现其他性能限制问题。共享池必须包含许多类型的对象,而库缓存对象只是这些类型之一。另外,内存是有限的资源。下面的小节将讨论影响Oracle在缓存中保存游标的各种方法。
Increase the Likelihood of Caching
Oracle无法释放打开的游标。即使共享池被刷新,打开的游标也被固定,因此无法释放。通常,当游标执行完成时,将关闭游标,游标固定被删除,如果没有其他会话固定游标,Oracle可以释放关联的内存。这允许新的和活动的游标保留在内存中,而较不活动的游标则自然释放。但是,如果解析成为一个重要的性能问题,作为性能分析人员,我们就会有动机影响Oracle将游标保存在内存中,一种方式是保持游标为打开状态。
Oracle允许我们保持游标比通常打开的时间更长。实例参数cursor_space_for_time当设置为true(缺省值为false)时,将所有游标固定,直到它们被特别关闭。即使在游标执行完成之后,Oracle也会保持游标固定,直到游标关闭为止。
但是,与所有调优更改一样,也有一个权衡。此实例参数影响整个Oracle实例中的所有游标。此外,它不是特定于会话的,参数更改需要实例重启才能生效。真正的含义是,现在需要更多共享池内存来缓存库缓存对象。实际上,这种影响可能非常显著,以至于共享池可能会有效地耗尽内存,从而导致可怕的4031“共享池内存耗尽”错误。所以在设置这个参数时必须小心。
就我个人而言,除非存在明显的解析问题(至少三种情况中的两种),否则我不会启用此选项:CPU消耗由解析时间和共享池latch争用或库缓存latch争用或互斥锁争用控制。相反,如果出现“out of shared pool memory”错误,请确保cursor_space_for_time被设置为false。
Force Caching
大多数dba都知道,确保大型包成功加载到共享池的一种方法是使用dbms_shared_pool.keep过程。当实例启动后立即将关键包加载到内存中时,收到“out of shared pool memory”错误的几率将显著降低。尤其是在早期版本的Oracle中,特别是在Oracle 8i中,这可以显著降低耗尽共享池内存的可能性。
下面是一个基于v$db_object_cache视图的OSM报告并且显示了在Oracle实例启动后被初始加载的对象。注意,生成报表时,共享池中没有强制保存符合报表选择标准的对象。
SQL> @dboc 10 20
old 9: where a.sharable_mem >= &min_size
new 9: where a.sharable_mem >= 20
old 10: and a.executions >= &min_exec
new 10: and a.executions >= 10
DB/Inst: jy/jy1 24-Apr 09:37am
Report: dboc.sql OSM by OraPub, Inc. Page 1
Oracle Database Object Cache Summary
Obj Exe Size
Owner Obj Name Type Loads (k) (KB) Kept?
------------ ----------------------------------- ---- ----- ----- ----- -----
SYS DBMS_STATS_INTERNAL PBDY 0 386 492 NO
SYS PLITBLM PKG 0 166 8 NO
SYS DBMS_ASSERT PBDY 0 49 16 NO
SYS STANDARD PBDY 0 27 32 NO
SYS DBMS_STATS_INTERNAL PKG 0 24 622 NO
SYS DBMS_SQLDIAG_INTERNAL PKG 0 18 12 NO
SYS DBMS_LOB PBDY 0 15 32 NO
DB/Inst: jy/jy1 24-Apr 09:37am
Report: dboc.sql OSM by OraPub, Inc. Page 2
Oracle Database Object Cache Summary
Obj Exe Size
Owner Obj Name Type Loads (k) (KB) Kept?
------------ ----------------------------------- ---- ----- ----- ----- -----
SYS DBMS_SQLDIAG PBDY 0 8 40 NO
SYS DBMS_SQL PBDY 0 3 74 NO
SYS DBMS_STANDARD PKG 0 1 48 NO
SYS DBMS_STATS PBDY 0 1 1213 NO
SYS DBMS_SQLTUNE_UTIL0 PBDY 0 1 16 NO
SYS DBMS_STATS_ADVISOR PKG 0 0 24 NO
SYS DBMS_SPACE_ADMIN PBDY 0 0 44 NO
DB/Inst: jy/jy1 24-Apr 09:37am
Report: dboc.sql OSM by OraPub, Inc. Page 3
Oracle Database Object Cache Summary
Obj Exe Size
Owner Obj Name Type Loads (k) (KB) Kept?
------------ ----------------------------------- ---- ----- ----- ----- -----
SYS DICTIONARY_OBJ_NAME FNC 0 0 8 NO
SYS DICTIONARY_OBJ_OWNER FNC 0 0 8 NO
SYS DBMS_UTILITY PKG 0 0 12 NO
SYS DBMS_UTILITY PBDY 0 0 57 NO
SYS DBMS_APPLICATION_INFO PBDY 0 0 8 NO
SYS IS_VPD_ENABLED FNC 0 0 8 NO
SYS DBMS_SPACE_ADMIN PKG 0 0 60 NO
DB/Inst: jy/jy1 24-Apr 09:37am
Report: dboc.sql OSM by OraPub, Inc. Page 4
Oracle Database Object Cache Summary
Obj Exe Size
Owner Obj Name Type Loads (k) (KB) Kept?
------------ ----------------------------------- ---- ----- ----- ----- -----
SYS DBMS_SQLTUNE_INTERNAL PBDY 0 0 532 NO
SYS DBMS_AUTO_TASK PKG 0 0 8 NO
SYS DICTIONARY_OBJ_TYPE FNC 0 0 8 NO
SYS PRVT_ADVISOR PBDY 0 0 176 NO
SYS AW_TRUNC_PROC PRC 0 0 8 NO
SYS DBMS_ADVISOR PBDY 0 0 69 NO
SYS DBMS_SQLTUNE_UTIL2 PBDY 0 0 20 NO
DB/Inst: jy/jy1 24-Apr 09:37am
Report: dboc.sql OSM by OraPub, Inc. Page 5
Oracle Database Object Cache Summary
Obj Exe Size
Owner Obj Name Type Loads (k) (KB) Kept?
------------ ----------------------------------- ---- ----- ----- ----- -----
SYS DBMS_SQLTUNE_UTIL1 PBDY 0 0 57 NO
SYS DBMS_OUTPUT PBDY 0 0 12 NO
SYS DBMS_STATS PKG 0 0 252 NO
SYS DBMS_PRIV_CAPTURE PBDY 0 0 12 NO
SYS DBMS_SPACE PKG 0 0 20 NO
SYS AW_DROP_PROC PRC 0 0 12 NO
SYS DBMS_ISCHED PBDY 0 0 387 NO
DB/Inst: jy/jy1 24-Apr 09:37am
Report: dboc.sql OSM by OraPub, Inc. Page 6
Oracle Database Object Cache Summary
Obj Exe Size
Owner Obj Name Type Loads (k) (KB) Kept?
------------ ----------------------------------- ---- ----- ----- ----- -----
SYS DBMS_SESSION PBDY 0 0 20 NO
36 rows selected.
SQL> l
1 select a.owner ownerx,
2 a.name namex,
3 decode(a.type,'PACKAGE','PKG','PACKAGE BODY','PBDY','FUNCTION','FNC','PROCEDURE','PRC') typex,
4 a.loads/1000 loadsx,
5 a.executions/1000 execsx,
6 a.sharable_mem/1024 sizex,
7 a.kept keptx
8 from v$db_object_cache a
9 where a.sharable_mem >= &min_size
10 and a.executions >= &min_exec
11 and a.type in ('PACKAGE','PACKAGE BODY','FUNCTION','PROCEDURE')
12* order by executions desc, sharable_mem desc, name
SQL>
当强制对象保存在共享池中时,请注意,Oracle最近使用最少的(LRU)共享池内存管理算法的影响。我们说的是我们比Oracle更了解。实际上可能就是这样,因为大多数dba都非常了解他们的应用程序。但是,在您这样做之前,将共享池装满诸如圣诞袜之类的包实际上会增加内存溢出错误的可能性,因为留给数百个(如果不是数千个)其他共享池对象的空间很小。所以,在使用这个程序之前要仔细考虑。
Private Cursor Caches
问题是:由于库缓存在所有会话之间共享,因此必须运行某种类型的序列化控制机制。无论机制是latches还是mutexes,这意味着获取控制结构与访问内存结构都是要消耗CPU资源的。如果访问变得紧张,可能触发大量的竞争,导致严重的性能下降。因此,就会问一个看似愚蠢但又合乎逻辑的问题:“我们能不能简单地不使用控制结构?”。
当然可以,如果序列化不是问题的话。Oracle所做的是通过为每个会话提供自己的私有库缓存结构来降低需要序列化库缓存访问的可能性,该结构只包含会话的常用游标(实际上只是指向游标的指针,这是它们的句柄)。因为游标缓存是私有的,序列化被保证,因此不需要控制结构!这确实是一个优雅的解决方案
这种私有库缓存结构也叫作会话游标缓存,缺省情况下,每个会话有一个游标缓存包含指向常用游标的指针。缺省情况下,Oracle 10gr2缓存20个游标指针。Oracle 11gr1是50个游标指针。不管缺省值是多少,缓存大小可以在系统级(不是会话级)通过修改session_cached_cursors实例参数来进行修改。
其过程如下:当运行一个SQL语句时,会话创建语句的哈值,然后检查句柄是否存在于自己的游标缓存中。因为没有其它进程能访问会话的游标缓存,不需要请求控制结构。如果句柄被找到,会话知道游标存在于缓存中。如果游标没有在会话游标缓存中找到,哈希值将被哈希到一个库缓存哈希桶中,获得合适的控制结构,然后序列化扫描链表,查找游标。如果句柄在会话的游标缓存中找到,虽然花费了一些精力进行解析,但它与硬解析是不一样的(语句没有在库缓存中找到)或者甚至与软解析也不一样(语句在库缓存中找到),因此术语软软解析(softer parse)用来描述这种方
法。
好消息就是库缓存(library cache)竞争可以通过增加每个会话的游标缓存来显著减少。坏消息是每个会话的游标缓存确实增加了。如果Oracle实例有几百个会话,所有会话游标缓存可能请求大量的内存进行导致共享池内存可用性的问题。当做得太过火时就会知道,因为将收到4031“out of memory”错误。在这时可以减小会话缓存大小或者如果有内存可用,增加共享池大小。因此,与几乎所有调优工作和参数一样,都要付出代价。作为性能分析师,我们希望成本小于性能收益。
Library Cache Latch/Mutex Contention Identification and Resolution
随着库缓存变得越来越活跃,对控制结构和控制结构占用时间的竞争可能会增加很多,从而成为一个严重的性能问题。当这种情况发生时,它将变得很明显,因为我们的响应时间分析将清楚地指向库缓存latch或与互斥锁相关的等待事件。此外,Oracle的CPU消耗将非常大,递归SQL或解析相关的时间将非常之多。操作系统将经受CPU瓶颈。幸运的是,有几个非常好的解决方案可以解决这个问题。
下面的脚本输出结果中可以看到几个library cache latch竞争,几乎100%的latch竞争是与library cache相关的。
SQL> @swpctx
Remember: This report must be run twice so both the initial and
final values are available. If no output, press ENTER twice.
DB/Inst: RLZY/RLZY1 26-Apr 08:52am
Report: swpctx.sql OSM by OraPub, Inc. Page 1
System Event CHANGE (5 sec interval) Activity By PERCENT
Time Waited % Time Avg Time Wait
Wait Event Display Name (sec) Waited Waited (ms) Count(k)
-------------------------------------- ----------- ------- ----------- --------
latch: library cache 3.580 55.50 41.1 0
latch: library cache pin 2.830 43.88 23.2 0
control file parallel write 0.030 0.47 1.5 0
direct path write 0.000 0.00 0.0 0
log file sync 0.000 0.00 0.0 0
log file parallel write 0.000 0.00 0.0 0
db file sequential read 0.000 0.00 0.0 0
启用Mutexes
下面的脚本输出结果与之前的唯一差别是通过设置实例参数_kks_use_mutex_pin为true(缺省值为true)来启用了library cache mutexes。注意top等待事件是cursor: pin S。结果就是游标正被重复地密集地打开与关闭。尽管在启用与禁用mutexes时递归SQL的百分比是相同的,但当使用latches时,总CPU消耗几乎是使用mutexes时的两倍。
SQL> @swpctx
Remember: This report must be run twice so both the initial and
final values are available. If no output, press ENTER twice.
DB/Inst: RLZY/RLZY1 26-Apr 08:54am
Report: swpctx.sql OSM by OraPub, Inc. Page 1
System Event CHANGE (5 sec interval) Activity By PERCENT
Time Waited % Time Avg Time Wait
Wait Event Display Name (sec) Waited Waited (ms) Count(k)
-------------------------------------- ----------- ------- ----------- --------
cursor: pin S 2.630 94.27 47.0 0
control file parallel write 0.030 1.08 1.5 0
direct path write 0.000 0.00 0.0 0
db file sequential read 0.000 0.00 0.0 0
log file parallel write 0.000 0.00 0.0 0
log file sync 0.000 0.00 0.0 0
使用绑定变量来创建类似SQL
Oracle对于它认为的类似SQL语句是非常讲究的。每个语句必须被解析,并且如果游标在library cache中没有找到,游标必须被完全构建(硬解析)。硬解析需要使用与库缓存相关的latches与锁,因此,如果硬解析变得如此强烈,相关的等待事件将被出现在报告的顶部,我们将寻找创建类似SQL语句的方法。Oracle提供了两种强大的方法来实现这一点。
第一方法是简单使用绑定变量来代替文本字。例如,语句select * from employee where emp_no=100使用文本值。如果语句select * from employee where emp_no=200被执行,因为Oracle的哈希算法,两个语句有不同的哈希值,将存放在不同的哈希桶中,并且有不同的handle。正如你所想的一样,当有密集的联机事务活动时,这将导致大量的硬解析。如果应用程序开发者可以提交这样的语句select * from employee where emp_no=:b1,使用绑定变量,游标将不会包含雇员号,并且游标可以高度重用(因为没有雇员号,相同的游标可以被重用)。这将显著减少硬解析。查看语句是否使用绑定变量非常简单。查看Oracle所存储的SQL,在v$sqltext中。如果使用绑定变量,您将看到它们。发现几个library cache相关的竞争可能导致你认识到绑定变量没有使用。应用程序开发者将非常不高兴,因为这需要大量的返工。
使用游标共享
另一种快速实现使用绑定变量的方法是让Oracle自动转换SQL语句。Oracle将有效地将没有使用绑定变量的SQL语句转换为使用绑定变量的语句。如果看到类似下面的语句就是Oracle自动转换的使用绑定变量的SQL:
select count(*) from customers where status != :"SYS_B_0" and org_id != :"SYS_B_1"
如果您非常了解应用程序SQL,那么您可能会意识到这个确切的SQL实际上并不存在于应用程序的任何地方。实际上,如果您检查了应用程序提交给Oracle的SQL,它可能是这样的。
select count(*) from customers where status != 'ACTIVE' and org_id != '15043'
结果就是你看到的Oracle自动转换SQL了使用它变得更容易共享。Oracle叫这个功能为cursor sharing(游标共享)。相关的实例参数为cursor_sharing,它有三个选项并且可以在会话级与系统级进行修改。当使用exact时,不会出现自动转换。当使用similar时,Oracle将寻找绑定变量并进行自动转换。当使用force时,Oracle会自动转换任何与每个文本值为绑定变量。
如果您向一组性能分析人员询问他们在游标共享方面的经验,您将立即得到一个看似矛盾而又充满激情的讨论。有些人,像我自己在使用similar选项时有美好的经历,其它人有各种各样的问题。有些人使用force选项后看到他们的SQL语句发生了巨大的变化并且SQL语句的结果集也不一样了。例如,原来返回10行记录的,现在只返回2行记录,有效的破坏了应用程序。
显然,您需要与您的同事交谈,与Oracle support进行检查,并测试特定环境中的各种选项。如果物理上无法更改SQL以使用绑定变量,或者非常痛苦,那么游标共享可以非常有效地工作。但是在生产环境中使用该选项之前,您必须非常勤奋地进行严格的测试。
利用哈希结构
从搜索角度来说,library cache是采用哈希结构来构建的。因此就像buffer cache chains一样,我们可以修改哈希桶的数量和latches的数量。当使用mutexes时,Oracle设置mutex内存结构关系。例如,每个library cache对象有属于自己的mutex。
根据Oracle版本的不同,Oracle实际上可能不会透露库缓存桶或锁存器的数量。例如Oracle 10gr2可能显示的library cache buckets的数量为9,library cache latches的数量为零。
Oracle允许通过实例参数_kgl_bucket_count来查看哈希桶的数量。library cache latches的数量是由实例参数_kgl_latch_count来控制的。现实中没有一个人通过增加生产系统中library cache哈希桶的数量并成功减少library cache latch竞争的。然而,就像cache buffer chain latches一样,library cache latch竞争可以通过增加library cache latches的数量来减少。
Try Mutex-Focused Solutions
当mutexes可用时,启用它们。可以通过将实例参数_kks_use_mutex_pin设置为false来禁用mutexes。如果你的系统正在遭受严重的mutex(互斥锁)问题,Oracle技术支持工程师可能会建议你关闭mutexes直到应用补丁为止。
大多数Oracle站点永远不会发生mutex(互斥)争用,如果发生mutex争用,那么压力可能与将游标固定在共享或独占模式有关。
有趣的是,要让互斥锁运行,操作系统必须支持比较和交换(CAS)操作。减少指令集计算机(RISC)操作系统,比如AIX或PA-RISC,可能选择通过消除比较和交换(CAS)操作来减少它们的指令集。在这种情况下,Oracle将通过使用一个latches池(在oracle 11gr1中缺省是有1024)池来模拟比较和交换(CAS)操作。latches被命名为KGX,并且可以通过修改实例参数_kgx_latches来改变它的数量,显然,这对于性能来说不是最优的,但是我们希望最终的结果是有益的。
SQL> select x.ksppinm NAME,y.ksppstvl value,x.ksppdesc describ
2 from x$ksppi x, x$ksppcv y
3 where x.inst_id=USERENV('Instance')
4 and y.inst_id=USERENV('Instance')
5 and x.indx=y.indx
6 and x.ksppinm like '%_kgx_latch%';
NAME VALUE DESCRIB
----------------- ------- -------------------------------------------------
_kgx_latches 1024 # of mutex latches if CAS is not supported.
实际上有许多与mutex(互斥)锁相关的等待事件。虽然我希望所有与mutex(互斥)锁相关的等待事件都是以mutex(互斥)锁开始,但是Oracle采取了不同的方法。与库缓存关联的mutex(互斥)对象都以单词cursor开头。这是有意义的,因为库缓存中充满了游标,但是它使性能分析人员更难发现新的mutex(互斥)对象的使用情况。
Mutex等待事件如下:
cursor:mutex X
当一个会话以排他模式请求一个mutex时,通过spinning不能获得因此进入休眠时将会post这个等待事件。只需要一个会话以共享模式持有mutex(互斥)锁,就可以防止排他性获取。构建一个子游标,捕获SQL绑定变量数据,构建或更新游标相关统计信息都需要以排他模式来请求mutex。
cursor: mutex S
当一个会话以共享模式请求一个mutex时,通过spinning不能获得因此进入休眠时将会post这个等待事件。多个会话可以以共享模式来持有一个mutex。如果一个mutex被另一个会话以排他模式所持有那么它将不能以共享模式被持有。当扫描引用计数时,一个会话以共享模式持有mutex,而不是排他模式。因此另外的会话可能正在更改引用计数。当出现这种情况时,mutex会被称为”正在变化中”。要看到这个事件是非常困难的,因为更改引用计数的速度非常快(有人告诉我,算法也建议这样做)。因此当多个会话以共享模式持有mutex时,更改引用计数实际上是一个串行操作。
cursor: pin S
当一个会话以共享模式请求pin(固定)一个游标时,通过spinning(自旋)不能完成因此而休眠时就会posts这个等待事件。多个会话可以以共享模式来pin(固定)一个相同的游标,但只能有一个会话以排他模式来持有一个mutex。Pinning将增加mutex的引用计数,这是一种序列化操作。因为一个会话必须pin(固定)一个游标才能执行游标(游标在执行期间不会被回收),当一个被频繁访问的游标被多个会话重复执行时可以在系统中看到这个等待事件。
cursor: pin X
当一个会话以排他模式请求pin(固定)一个游标时,通过spinning(自旋)不能完成因此而休眠时就会posts这个等待事件。只需要一个会话以共享模式固定mutex(互斥)锁,就可以防止排他性占有。当创建游标时必须以排他模式来固定。你不想在同一时刻其它的会庆创建或修改相同的游标。
cursor: pin S wait on X
当一个会话以共享模式来pin(固定)游标时,因为另外的会话以排他模式持有mutex而必须等待时就会posts这个等待事件。例如,如果一个会话只想简单地执行游标,它必须以共享模式来请求mutex。然而,当会话正在执行游标时,如果另外的会话正在构建或修改游标(请求以排他模式来固定),将会post这个等待事件。当多个会话想执行这个游标时而游标正在被重建(可能基表已经被修改了)时就会看到这个等待事件。
解决互斥锁相关争用的关键是同时理解等待事件和应用程序中正在发生的事情。例如,如果等待事件是cursor:pin S(最可能的),可能是相同的cursor被一些用户重复执行,几个游标被许多用户执行,甚至一个简单的SQL语句是由数百个用户并发执行。理解了这一点之后,您将寻找执行频率相对较高的SQL语句,并尽一切可能降低其执行频率。使用等待事件让你了解与游标相关的特殊情况,并了解应用程序的性质,这是最佳的解决方案路径。
同样,互斥锁等待不太可能是最重要的等待事件(当没有相关的互斥锁错误时),但它偶尔会发生。因此,理解互斥锁序列化控制以及库缓存内部结构和诊断是非常重要的。