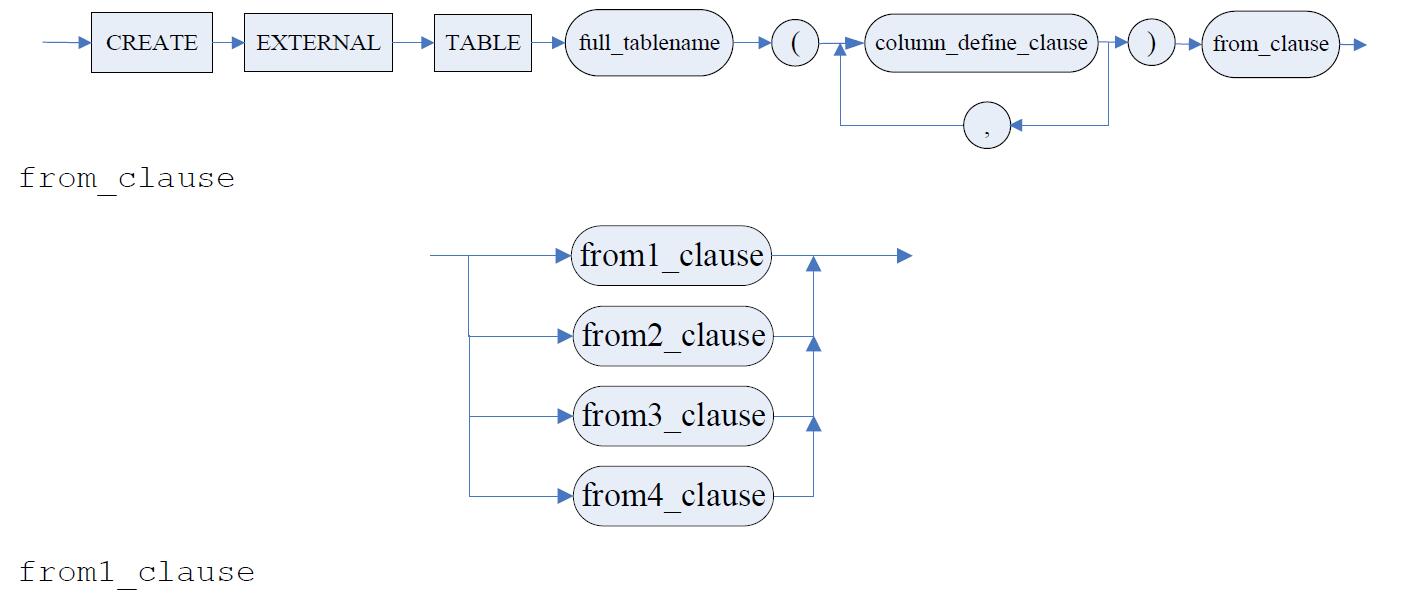
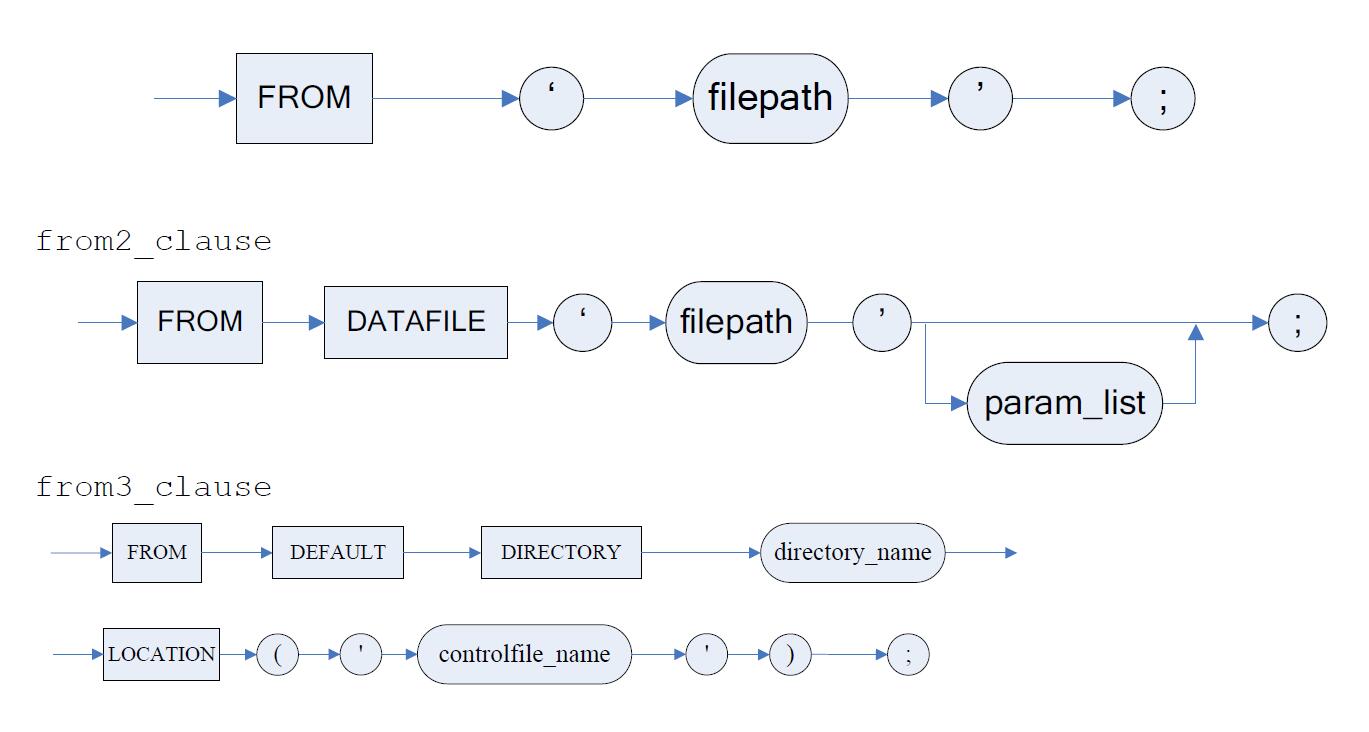
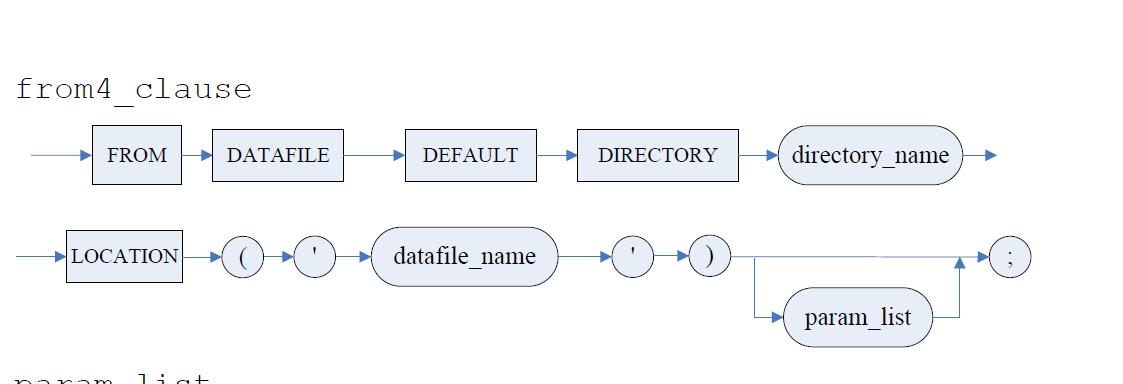
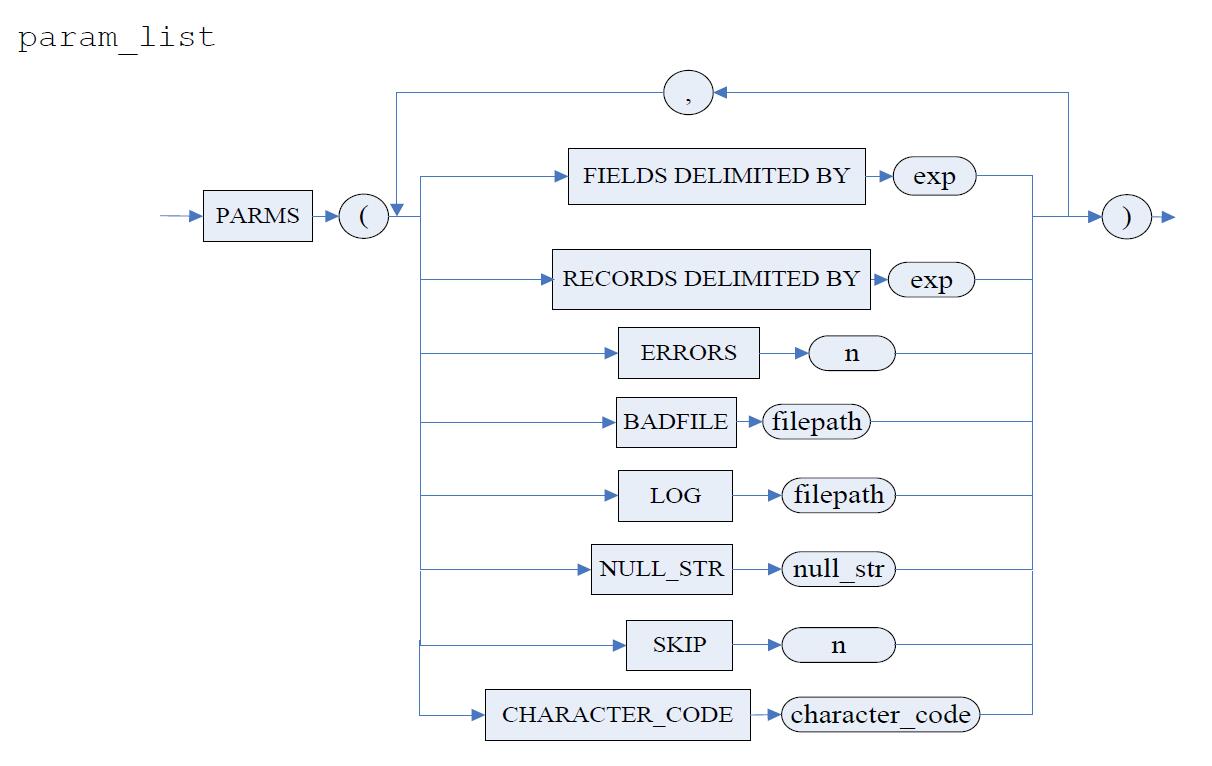
DM自增列的使用
DM自增列定义
1.自增列功能定义
在表中创建一个自增列。该属性与CREATE TABLE语句一起使用,一个表只能有一个自增列。
语法格式
IDENTITY [ (种子, 增量) ]
参数
1.种子 装载到表中的第一个行所使用的值;
2.增量 增量值,该值被添加到前一个已装载的行的标识值上。增量值可以为正数或负数,但不能为0。
使用说明
1.IDENTITY 适用于int(-2147483648~+2147483647)、bigint(-263~+263-2)类型的列;每个表只能创建一个自增列;
2.不能对自增列使用DEFAULT 约束;
3.必须同时指定种子和增量值,或者二者都不指定。如果二者都未指定,则取默认值(1,1);若种子或增量为小数类型,报错;
4.最大值和最小值为该列的数据类型的边界;
5.建表种子和增量大于最大值或者种子和增量小于最小值时报错;
6.自增列一旦生成,无法更新,不允许用Update语句进行修改;
7. 临时表、列存储表、水平分区表、垂直分区表不支持使用自增列。
2.自增列查询函数
1) IDENT_SEED(函数)
语法格式:
IDENT_SEED (‘tablename’)
功能:返回种子值,该值是在带有自增列的表中创建自增列时指定的。
参数:tablename:是带有引号的字符串常量,也可以是变量、函数或列名。tablename的数据类型为char或varchar。其含义是表名,可带模式名前缀。
返回类型:返回数据类型为int / NULL
2) IDENT_INCR(函数)
语法格式:
IDENT_INCR (‘tablename’)
功能:返回增量值,该值是在带有自增列的表中创建自增列时指定的。
参数:tablename:是带有引号的字符串常量,也可以是变量、函数或列名。tablename的数据类型为char或varchar。其含义是表名,可带模式名前缀。
返回类型:返回数据类型为int / NULL
例如用自增列查询函数获得表PERSON_TYPE的自增列的种子和增量信息。
SQL> SELECT IDENT_SEED('PERSON.PERSON_TYPE');
LINEID IDENT_SEED('PERSON.PERSON_TYPE')
---------- --------------------------------
1 1
used time: 1.529(ms). Execute id is 46903.
SQL> SELECT IDENT_INCR('PERSON.PERSON_TYPE');
LINEID IDENT_INCR('PERSON.PERSON_TYPE')
---------- --------------------------------
1 1
used time: 0.956(ms). Execute id is 46905.
SET IDENTITY_INSERT 属性
设置是否允许将显式值插入表的自增列中。
语法格式
SET IDENTITY_INSERT [< 模式名>.]< 表名> ON | OFF;
参数
1.< 模式名> 指明表所属的模式,缺省为当前模式;
2.< 表名> 指明含有自增列的表名。
使用说明
1.IDENTITY_INSERT属性的默认值为OFF。SET IDENTITY_INSERT 的设置是在执行或运行时进行的。当一个连接结束,IDENTITY_INSERT属性将被自动还原为OFF;
2.DM要求一个会话连接中只有一个表的IDENTITY_INSERT 属性可以设置为ON,当设置一个新的表IDENTITY_INSERT 属性设置为ON时,之前已经设置为ON的表会自动还原为OFF。当一个表的IDENTITY_INSERT 属性被设置为ON时,该表中的自动增量列的值由用户指定。如果插入值大于表的当前标识值(自增列当前值),则DM自动将新插入值作为当前标识值使用,即改变该表的自增列当前值;否则,将不影响该自增列当前值;
3.当设置一个表的IDENTITY_INSERT 属性为OFF时,新插入行中自增列的当前值由系统自动生成,用户将无法指定;
4.自增列一经插入,无法修改;
5.手动插入自增列,除了将IDENTITY_INSERT设置为ON,还要求在插入列表中明确指定待插入的自增列列名。插入方式与非IDENTITY表是完全一样的。如果插入时,既不指定自增列名也不给自增列赋值,则新插入行中自增列的当前值由系统自动生成。
举例说明
例如SET IDENTITY_INSERT 的使用
1) PERSON_TYPE表中的PERSON_TYPEID列是自增列
SQL> select * from person.person_type; LINEID PERSON_TYPEID NAME ---------- ------------- -------- 1 1 采购经理 2 2 采购代表 3 3 销售经理 4 4 销售代表 5 9 卫生员 6 10 保洁员 6 rows got used time: 12.207(ms). Execute id is 46927.
2) 在该表中插入数据,自增列的值由系统自动生成。
SQL> INSERT INTO PERSON.PERSON_TYPE(NAME) VALUES('销售总监');
affect rows 1
used time: 0.884(ms). Execute id is 46930.
SQL> INSERT INTO PERSON.PERSON_TYPE(NAME) VALUES('人力资源部经理');
affect rows 1
used time: 0.749(ms). Execute id is 46931.
SQL> commit;
executed successfully
used time: 21.221(ms). Execute id is 46933.
SQL> select * from person.person_type;
LINEID PERSON_TYPEID NAME
---------- ------------- --------------
1 1 采购经理
2 2 采购代表
3 3 销售经理
4 4 销售代表
5 9 卫生员
6 10 保洁员
7 11 销售总监
8 12 人力资源部经理
8 rows got
used time: 0.445(ms). Execute id is 46934.
3) 当插入数据并且要指定自增列的值时,必须要通过语句将IDENTITY_INSERT设置为ON 时,插入语句中必须指定PERSON_TYPEID 中要插入的列。例如:
SQL> SET IDENTITY_INSERT PERSON.PERSON_TYPE ON; executed successfully used time: 32.673(ms). Execute id is 46938. SQL> INSERT INTO PERSON.PERSON_TYPE(PERSON_TYPEID, NAME) VALUES( 14, '广告部经理'); affect rows 1 used time: 0.966(ms). Execute id is 46941. SQL> INSERT INTO PERSON.PERSON_TYPE(PERSON_TYPEID, NAME) VALUES( 15, '财务部经理'); affect rows 1 used time: 0.788(ms). Execute id is 46943. SQL> commit; executed successfully used time: 25.501(ms). Execute id is 46944. SQL> select * from person.person_type; LINEID PERSON_TYPEID NAME ---------- ------------- -------------- 1 1 采购经理 2 2 采购代表 3 3 销售经理 4 4 销售代表 5 9 卫生员 6 10 保洁员 7 11 销售总监 8 12 人力资源部经理 9 14 广告部经理 10 15 财务部经理 10 rows got used time: 0.467(ms). Execute id is 46945.
4) 不允许用户修改自增列的值。
SQL> UPDATE PERSON.PERSON_TYPE SET PERSON_TYPEID = 14 WHERE NAME = '广告部经理'; UPDATE PERSON.PERSON_TYPE SET PERSON_TYPEID = 14 WHERE NAME = '广告部经理'; [-2664]:Error in line: 1 Try to alter identity column [PERSON_TYPEID]. used time: 0.565(ms). Execute id is 0.
5) 还原IDENTITY_INSERT属性。
SQL> SET IDENTITY_INSERT PERSON.PERSON_TYPE OFF; executed successfully used time: 0.597(ms). Execute id is 46951.
6) 插入后再次查询。注意观察自增列当前值的变化。
SQL> SET IDENTITY_INSERT PERSON.PERSON_TYPE OFF;
executed successfully
used time: 0.597(ms). Execute id is 46951.
SQL> INSERT INTO PERSON.PERSON_TYPE(NAME) VALUES('市场总监');
affect rows 1
used time: 1.013(ms). Execute id is 46954.
SQL> commit;
executed successfully
used time: 16.449(ms). Execute id is 46955.
SQL> select * from person.person_type;
LINEID PERSON_TYPEID NAME
---------- ------------- --------------
1 1 采购经理
2 2 采购代表
3 3 销售经理
4 4 销售代表
5 9 卫生员
6 10 保洁员
7 11 销售总监
8 12 人力资源部经理
9 14 广告部经理
10 15 财务部经理
11 16 市场总监
11 rows got
used time: 1.000(ms). Execute id is 46956.